WHITEPAPERS
Data Wrangling for IoT Analytics
Discover the key aspects of data wrangling in IoT analytics, its impact on data quality, success strategies, and real-world applications in this guide.
Author: Elaad Applebaum
Sr. Data Scientist
As a Sr. Data Scientist at Very, Elaad applies machine learning methods to find creative yet understandable solutions to address client needs while also ensuring that the products work reliably end-to-end.

Author: Daniel Fudge
Director of ML and Data Engineering
Daniel leads the data science and AI discipline at Very. Driven by ownership, clarity and purpose, Daniel works to nurture an environment of excellence among Very’s machine learning and data engineering experts — empowering his team to deliver powerful business value to clients.

Unlocking the Power of Data
Data wrangling: it’s a bit like cowboys breaking a bronco. No, it doesn’t involve a lasso and spurs. But, akin to taming wild horses for domestic use, data wrangling involves collecting raw, wild, unruly data and transforming it into something ultimately useful in business applications.
In this article, we’ll dive into the key aspects of data wrangling and how it’s used in IoT analytics. Let’s begin by examining the definition of data wrangling.
Data Wrangling Defined
Data wrangling (also known as data munging or data remediation) is the process of taking raw data and transforming it into a usable format. By “usable,” we mean ready for further analytics, such as in a report, dashboard, or machine learning model. It involves gathering data from various sources, understanding its structure and quality, and manipulating it to ensure its accuracy, consistency, and completeness.
Data wrangling is often confused with data cleaning, but the two terms aren’t interchangeable. Data cleaning is one step of many in the data wrangling process, which we’ll describe in more detail later on.
IoT Analytics: Uses and Benefits
IoT analytics refers to the application of data analytics tools to internet-enabled devices. Like traditional data analytics, the goal of IoT analytics is to use data to inform decision-making, derive insights, or automate processes. The difference here is that IoT analytics uses data collected from the edge. With connected devices generating data from new sources, IoT analytics can deliver visibility and process control which would have been previously impossible. Users – or automated systems – can make real-time decisions that reduce costs, increase efficiency, and improve quality, all informed by data at the edge.
IoT analytics products do things like displaying historical and real-time data on dashboards, or generating reports to increase visibility into systems and processes. Artificial intelligence (AI) and machine learning (ML) applications also play a key role in IoT analytics. AI and machine learning in IoT can be used to automate previously manual processes and workflows, from remote monitoring and predictive maintenance applications to physical security.
Data Wrangling in IoT Analytics: Why Does It Matter?
In any analytics application, data wrangling is a must. But why? Data wrangling ensures consistent data with fewer errors, facilitating more accurate decision-making. Through data wrangling, data becomes more usable and can be structured to complement downstream analytics and business needs. This also means less time is wasted sifting trends from noise.
It’s often estimated that the time spent wrangling data far outweighs the time spent building machine learning models. Most modeling approaches require well-structured, clean data, with data from various sources combined into one dataset — including labeled data, if that’s being used.
As compared to “traditional” data, IoT data brings its own set of challenges. The data may come from a variety of sources, with different data types and structures. Data collection is often a challenge on its own, as edge devices may be limited in their resources or connectivity. As a result, there may be more gaps or data errors to be addressed in addition to the inherent noise in the measurements. IoT devices can also generate massive volumes of real-time data — as the number of connected devices increases, we quickly enter the realm of “big data.” These challenges necessitate even greater attention to the important process of data wrangling.
Who’s Responsible for Data Wrangling?
At Very, data wrangling is a cross-functional enterprise. Our data engineers and data scientists are primarily responsible for wrangling data, but they work with others throughout the process, including hardware, firmware, and software engineers. They also collaborate with subject matter experts and non-technical stakeholders.
Data engineers usually spearhead the bulk of tasks related to collecting data and structuring, whereas data scientists drive the analytical side, like data exploration and enrichment.
Data wrangling is often a manual process. At Very, however, we emphasize reliability and scalability of our systems. To that end, we productionize our data wrangling steps in automated pipelines as soon as we can.
Explaining the IoT Data Lifecycle: From Data Generation to Analytics
IoT data undergoes a long journey before arriving on a dashboard or machine learning model.
First, data is generated on the edge from all kinds of sources, including telemetry data from sensors, image data from cameras, and data from industrial control systems. In a cloud-based application, the data is collected on the edge, where some data processing may occur before forwarding the data to the cloud. Often, this data will then be stored as-is with only minimal alteration in what is known as a data lake.
Data processing continues, including combining data from different sources, handling missing data, scrubbing bad data, and reformatting and aggregating values. At this point, the data may be made available to a dashboard, or continue on to machine learning models, which will make predictions based on that incoming data. In edge applications, most of the same above steps are still performed on data, except they occur exclusively on the edge device.
How Data Wrangling Impacts the Quality of IoT Analytics
Every data processing step in the IoT data lifecycle is actually a data wrangling step that has been codified in a data pipeline. Engineers wrangle data to make sure it’s not only usable, but useful. Data wrangling ensures relationships between data can be uncovered and visualized, that noise in the data doesn’t drown out the signal, and that data errors don’t introduce aberrant results.
There is an old saying in the data community: “garbage in, garbage out.” Your insights, predictions, and decisions are only as good as the data you feed into your analyses and models. The task of data wrangling is in many ways, then, the task of ensuring that the data input to our analysis is of the highest possible quality — whether that means filtering or correcting bad data, enriching data via transformations or external sources, or restructuring data to be more digestible.
Every choice that’s made throughout the data wrangling process ultimately influences the downstream analyses. For example, in the face of missing data from an observation, we have the option to delete the observation altogether. We could impute the data (substitute the missing value with an estimate based on other available data), or leave the missing value and assume our analyses or models can handle it. Each of these options will require a unique approach.
The approach taken could introduce or remove statistical biases, add computational overhead, or lead to incomplete analyses. Choosing the right approach requires an understanding of the underlying data, the relevant business requirements, and the statistical implications of the choice. It may also require experimentation to settle on a decision.
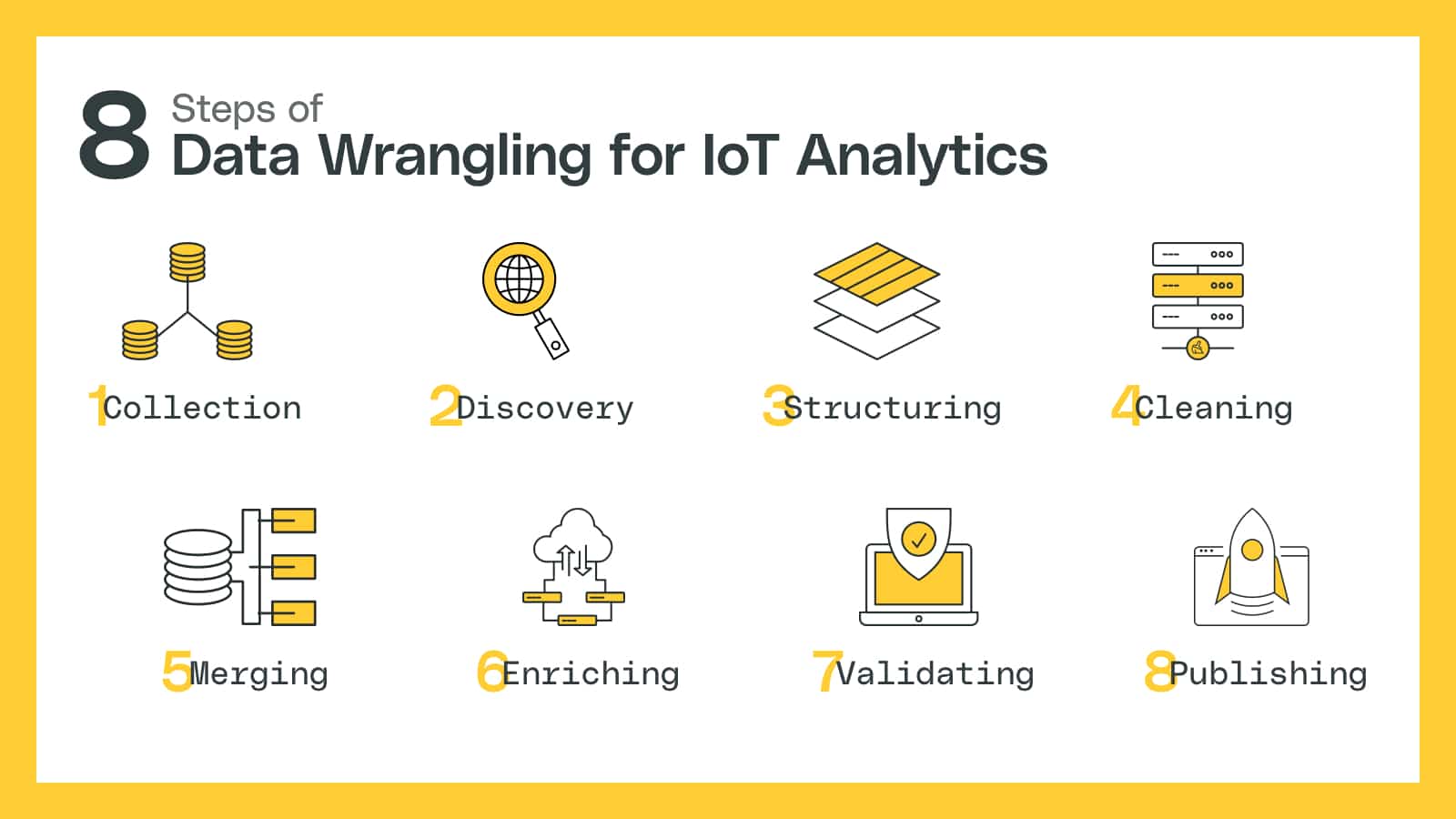
Steps in Data Wrangling for IoT Analytics
There are several steps traditionally included under the data wrangling umbrella. They’re usually depicted as a one-time process, transforming a set of raw data into a set of publishable data through a sequence of actions performed in series. In reality, though, data wrangling is an ongoing process.
In line with Very’s practice of Agile IoT development, we approach data wrangling iteratively, repeating and revising steps to continually enhance the value of our analyses and machine learning models. Additionally, as data streams continuously from IoT devices, these steps are automated into pipelines that continuously prepare data for use in the product. This cyclical or loop-like approach can be described as the “data wrangling loop.”
The steps involved in the data wrangling loop are:
- Collection
- Discovery
- Structuring
- Cleaning
- Merging
- Enriching
- Validating
- Publishing
1. Data Collection
Data collection isn’t usually included as a data wrangling step, but in IoT analytics, it’s a crucial underpinning of all that follows. One of the first problems to solve is how to ingest data from sensors so that a data scientist — and later, your application — can explore it. Data collection is solved via a cross-functional team, including hardware engineers, firmware engineers, data engineers, and data scientists.
2. Data Discovery
Many of the choices that will be made in later steps depend on the characteristics of the data and the data generation process. The first thing a data scientist needs to do with data is understand what they’re looking at. They have to identify the type of data they’re dealing with, how the data is structured, what information is available, what’s missing, trends and patterns, issues that must be addressed, and insights that can be utilized later. At Very, data discovery is also a cross-functional exercise; data experts work with hardware and firmware engineers to understand the data generation process, with subject matter experts to better understand data characteristics and trends, and with business leaders to define downstream product requirements that target searches for data issues to be mitigated.
3. Data Structuring
Data is unstructured in its raw form and it’s the job of software to provide structure — often in the form of records and fields (rows and columns). Yet, the structuring approach isn’t one-size-fits-all; it flexibly changes to fit the specific analytical needs at hand. Typically, some amount of structure is imposed on the data during the data collection stage, but additional structuring may be necessary. Structuring may take the form of restructuring by converting data from one format (like JSON) to another (like CSV). This could include extracting values into new fields, combining multiple data elements into one field, recording data, pivoting data, or aggregating data. As you’ve likely gathered by now, data wrangling is not a linear process. Data structuring, for instance, will be repeated multiple times and often alternates with other steps like cleaning or enriching.
4. Data Cleaning
Data cleaning removes or corrects errors in the data that might negatively affect later analyses. Errors come in many forms — there could be missing data, duplicated data, incorrect or inconsistent encodings, misspelled words, inconsistent units of measure, or inconsistent data types. Additionally, personally identifiable information (PII) may need to be removed or anonymized.
Many of the common data issues will have already been identified during the discovery phase; ideally, approaches to correct errors will be informed by underlying knowledge of how the errors were introduced. Otherwise, a data scientist may use a combination of statistical approaches and ad-hoc reasoning to find the best path forward, as well as an understanding of how the data will ultimately be used in later analyses or machine learning models.
As with data structuring, data cleaning is a step that’s generally repeated several times. In particular, many of the inconsistencies may appear after merging data from multiple sources. For example, if combining data from multiple devices or sensors that were configured differently, it’s important to standardize their data before consolidating them into one dataset.
5. Data Merging
Data merging is not typically considered its own step, but it’s so common in IoT analytics that we like to mention it separately. Data merging is the combining of data from multiple sources into a single dataset. This may happen many times in an IoT product — we may combine data from multiple sensors, devices, locations, or facilities. Different types of data may be combined at various stages — for example, we may combine telemetry data from sensors with process data from a scheduling system, or image data from a camera with geolocation information.
6. Data Enriching
Data enriching involves the derivation of new data from existing data. We may add metadata, such as device IDs or relevant timestamps. We may derive new data by applying thresholds or bucketing, such as converting a battery percentage below some value to a “low battery” field. Data may undergo more complex enrichment, often requiring domain knowledge or outside information, such as converting latitude and longitude to zip codes or positions and speeds into cycle counts.
7. Data Validating
We validate our data every step of the way, but we’ll note it here separately for added emphasis. Data validation confirms that the data successfully conforms to the changes we intended to make, including ensuring data types are correct, that data values fall in an expected range, and that data are structured the way we expect. The best way to validate data is to implement automated testing. At Very, testing is deeply ingrained in all our engineering and data science.
8. Data Publishing
Data publishing means making the data — now transformed into a usable form — available for further analysis. The published data can be stored and used for a wide array of purposes, including supplying data for a database that serves a dashboard, saved as training data for a machine learning model, or forwarded on to other parts of the system that aid in decision making.
Another, Oft-forgotten Step: Automation
At Very, we consider automation to be an important and ever-present component of data wrangling. Once the details of a data wrangling process are determined, we ensure the IoT product we are building can process the data automatically. In fact, we often don’t distinguish between data wrangling, data processing, and data pipelining; data from IoT devices is collected continuously, and it’s important to ensure that new data also consistently provides value. Depending on the requirements of the product, some of these steps may be performed on the edge, while others may occur in the cloud.
Challenges in Data Wrangling for IoT Analytics
Managing High Volume and Velocity for Real-Time Analytics
A frequent use case in IoT analytics is processing streaming data — real-time data that is continuously generated, collected, and processed. Streaming applications often need to process data quickly (with sub-second latencies) while scaling up to high volumes.
In these cases, data wrangling techniques need to be tailor-made to the requirements of the product. Data cleaning and error correction should be lightning-fast. Multiple data sources must not only be merged, but collected quickly and accurately. When transformations require knowledge of historical data, such as certain aggregation operations, error-correction techniques, and gap-filling approaches — then either your stream processing pipelines have to maintain state efficiently, or you need to revise your data wrangling techniques — and possibly your product requirements — to be stateless.
Building Robust Data Pipelines
Even the best designed systems will at some point encounter a problem. Think of unanticipated missing data, unexpected data types and values, out-of-order or duplicate data, and much more. Once a data wrangling pipeline has been automated and deployed to a production system, it’s crucial to ensure that unexpected data doesn’t crash the system or lead to data loss. At Very, we work hard to ensure our data pipelines are reliable from the start.
Our same best practices that apply to other aspects of our products are applied to our data wrangling pipelines, such as test-driven development. Not only is data validation one of the most important data wrangling steps, but it should come first whenever possible. When designing our tests and validations, we think ahead to capture as many problem scenarios as possible, even if we haven’t seen them in real data. Automating multiple levels of testing, including unit tests, integration tests, and end-to-end tests helps to catch and prevent problems early.
Some errors will inevitably occur in production, and we design our systems to be fault-tolerant in order to ensure a failure in one step does not necessarily lead to failure in another. By loosely coupling different steps, we ensure the rest of the pipeline remains healthy. We decide on a plan when issues occur: do we drop the problem data, reattempt, or continue processing it after skipping a step? We also ensure as much visibility into the system as possible, by logging errors at the point of failure, so if changes to the code are necessary, we can quickly address the issue and deploy a fix.
Navigating the Impact of Data on Hardware and Vice-Versa
When data is not of the desired quality or quantity, it can impact not just analytical outcomes but also the broader ecosystem, including hardware design. Hardware constraints and modifications, in turn, may drive changes in the pipeline. As we handle real-time data streams, ensuring rapid data cleaning, merging of multiple sources swiftly, and managing stateful transformations become critical. Consequently, any deviation in hardware design or unexpected data types can lead to adjustments in the data wrangling loop, emphasizing the need for a robust and fault-tolerant pipeline.
Tools and Techniques for Data Wrangling in IoT Analytics
Introduction to Data Wrangling Tools Suitable for IoT Analytics
Data wrangling requires several tools. For wrangling data from a relational database (or multiple databases), SQL is the typical go-to as it’s capable of operating and merging data efficiently and scalably. For more complex transformations — and for handling raw data that is not yet formatted in rows and columns — we rely on languages like Python that have advanced libraries for transforming data and can be incorporated into production software. Other use cases may benefit from other tools; wrangling data on an edge device may require porting some of the data processing steps to embedded C, while handling large volumes of data in the cloud can be accomplished using Apache Spark.
Can Machine Learning and AI Help in Data Wrangling?
While data wrangling is essential for building machine learning products, machine learning is also increasingly used in the data wrangling process itself. Machine learning can be used to fill in missing data, detect and anonymize personally identifiable information, or link different records when merging data.
Case Studies: Data Wrangling in IoT Analytics in Action
SUN Automation
Very built a robust predictive maintenance solution for SUN Automation Group, a global leader in corrugated manufacturing solutions. From the beginning, data wrangling underpinned the success of the product.
We began by collecting telemetry data gathered from programmable logic controllers (PLCs). Once ingested from the PLCs, the data was structured and sent to the cloud to be cleaned, including filling gaps in the data. The data was then enriched, with calculations informed by subject matter experts transforming the raw data from the PLC into useful metrics that could be sent to the dashboard. The now clean and structured telemetry data could be stored in a backend database to be queried by users in the analytics dashboard.
From there, pipelines further aggregated and reformatted the data. It was stored so machine learning algorithms could train anomaly detection models. The data was merged with data from scheduling and tracking systems, which were ultimately used to train downtime prediction models. Real-time data were fed to the anomaly detection and downtime prediction models; these predictions were themselves merged into the backend database and made available to users to monitor the health of their manufacturing systems.
Hayward Pools
Hayward Pools wanted to leverage the large amounts of data it was generating to better serve customers. By combining user data, pool configurations, and regional information, the pool company aimed to leverage this data to identify opportunities for their customers to optimize their pool systems through useful insights, reminders, and warnings about their current and future operations.

To achieve this, the Very team performed a data unification exercise, collecting and aggregating the data from disparate services, IoT devices, and data storage systems. By creating a data lake, the Very team could centralize and clean the data, effectively normalizing, deduplicating, and enriching it. In doing so, the data became more suitable for analysis and the team was able to create complex data pipelines that would ultimately result in new, mission-critical datasets.
Very employed several strategies while cleaning the data, such as address verification and validation using Google Geocoding API. Other strategies included using data science to perform data unification on user data to create a true user profile containing user information from multiple systems. Additionally, the team used the pool configuration data which was retrieved from IoT devices spread across the United States. With these configurations, Hayward could identify various opportunities to enhance the user experience by recommending things like water heaters for customers within certain regions — enabling their customers to enjoy their pools for a longer period of time.
The Future of Data Wrangling in IoT Analytics
Research firm IoT Analytics reports that the number of connected IoT devices continues growing at a fast pace – with more than 16 billion devices expected by the end of 2023. As the number of IoT devices grows, the amount of data generated by these devices will also increase. With more data coming from more sources, we can expect the importance of data wrangling in IoT analytics to only increase.
Data security and privacy continue to be top of mind as well, and we can expect more of the data wrangling process to be devoted to maintaining data privacy. As regulations increase and consumers become more attuned to how their data is used, IoT analytics products will need to work harder to anonymize personally identifiable information.
As real-time applications continue to proliferate, expectations for latency between data generation and insights also continue to shrink. As a result, an increasing number of IoT applications are pushing most or all of their computing to the edge. In these products, all of the data wrangling steps will occur in resource-constrained devices where every bit of memory or processing must be carefully optimized. We can expect the continued development of techniques and tools to wrangle data in these extreme environments.
Predictions for Data Wrangling Techniques in IoT Analytics
Given the exploding popularity of IoT analytics applications, we can expect new platforms for automated data wrangling to emerge. However, data wrangling is a complex process that requires a fundamental understanding of the data, deep consideration of product requirements, and iterative development in the context of tight feedback loops. While new tooling may speed up some of the steps, experienced data scientists and data engineers will continue to be irreplaceable in addressing the growing data wrangling challenges in IoT products.
Embracing Data’s Transformative Power
IoT is a rapidly growing market, with billions of connected devices generating enormous volumes of data. The central goal of IoT analytics is to derive value from these mountains of data by automating processes, providing actionable insights to decision-makers, and shining a light on previous blind spots. However, the growth in IoT data – in volume, velocity, and variety – opens the door to new opportunities as well as challenges. Before any of the data can be analyzed, it must first be structured, cleaned, and contextualized with other relevant data sources. This process, known as data wrangling, serves as the foundation for all downstream analytics. Without thoughtful yet efficient data wrangling steps, an IoT analytics product will be much like raw data: full of potential, but ultimately of limited value.