BLOG
How to Build Smart Connected Products That Last

What happens when we lose the “I” in IoT?
Internet of Things devices are defined by their interconnectivity. Whether that means being connected to the cloud over a Wi-Fi network or using Bluetooth to talk to a user-end mobile app, smart devices are connected devices. While having full connectivity on a reliable network is our ideal condition, that’s simply not always the reality. Sometimes the internet goes down, the power goes out, or even the company that manages the device’s cloud service goes out of business.
What happens then?
IoT developers need to create connected products that last. That’s why we design redundancy and fault-tolerance measures from the very beginning.
Of course, different use cases have different thresholds that we need to meet.
For instance, while it’s important that a consumer-facing smart product works as intended, the consequences of failure are much lower than an industrial internet of things (IIoT) device that controls heavy machinery. We expect a jet engine to have much more fault-tolerance than color-changing smart lights for good reason.
To get to the heart of this issue, we’re going to start by looking at the big picture strategy that goes into designing robust smart devices. We’ll then discuss specific technologies that Very uses to meet these objectives.
Big Picture Strategy for Developing Connected Products
Before we start building device hardware or even write a single line of code, we sit down with our clients to draw a product roadmap. Besides nailing down features and discussing logistics, we make sure to ask about the contingencies of what could go wrong and how we should handle them.
We’ll ask questions like:
- What should happen if the device loses its internet connection?
- What happens if we lose our power supply?
- What are the implications of this device failing?
- What amount of risk can we assume?
This strategy conversation lets us work through these possibilities and, if necessary, write device firmware to deal with them.
Example: KEEP Labs

Let’s make this a little more concrete by going through an example. Very recently partnered with KEEP Labs to build KEEP, a device designed for smart medicinal storage recently recognized by TIME as one of the 100 Best Inventions of 2020. KEEP provides sensor data on metrics like internal temperature & humidity, but more importantly, it’s got a smart lock that lets users unlock and monitor KEEP with a mobile app.
When we want to open KEEP, we’ll press a button on our phone, which then sends a request up to a cloud server. The cloud, in turn, tells the device’s firmware to open the lid. But, since KEEP Labs wanted to make sure that their product functions even if a user loses their internet connectivity, we can also use Bluetooth to directly interface with KEEP.
We also planned for the possibility of power outages. Especially in California, which often experiences rolling blackouts, users still need a way to get to their prescriptions and cannabis when the lights go out. That’s why we made sure to include a high-capacity battery as a redundant power supply.
The key point is that we thought ahead about these problems before we encountered them, and we planned accordingly. Even if we decide that we don’t need a plan for every single contingency, it’s important that we talk about them upfront so that we have a clear view of our priorities.
Technology for IoT Developers
Building redundant, fault-tolerant systems is very much a part of our approach to the IoT tech stack, so we want to give you an overview of some of the solutions that we use. A big part of this is a software development technique called defensive programming.
This means that all our code should have a plan for errors, and we bake this into our applications while we write them. That way, even if our program does crash or we encounter an unexpected problem, we can reduce the blast radius and mitigate the damage. This could mean isolating the issue, automatically trying to restart the program, or even triggering a full system reboot.
This is the main reason why Elixir is our go-to language for developing connected products. Elixir leverages the power of the Erlang VM, which is designed with fault-tolerance in mind, and as a result, it promotes defensive programming habits.
Take, for instance, the way Elixir/Erlang treats processes. Instead of running all our code in the same space, we break functionality into discrete parts, which we can then isolate as processes. Elixir code can run up to millions of concurrent processes.
There are some distinct advantages to this approach. First, if one process dies, then it won’t crash our entire application—we might just lose a bit of functionality.
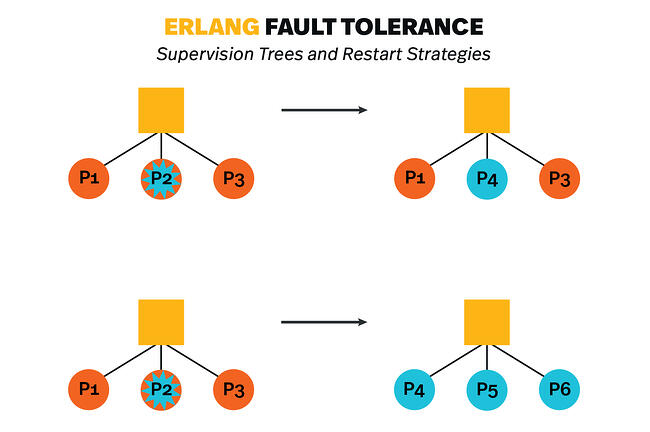
Second, we can structure processes hierarchically by using supervisors, which are basically processes that monitor other processes. We then configure these supervisors to act based on our contingencies. This could be restarting a dead process, sending an error report, or anything else that we need.
Pictured below is an example of one of the restart strategies enabled by Elixir/Erlang, where a supervisor restarts all processes when one process dies. However, as mentioned above, you can also arrange your supervisors so that only the process that fails restarts, or so that the system will restart processes based on the order they were created and which ones failed.
The key here is that Elixir isn’t the first language to take this process-based approach to programming, but rather that doing so is much easier than in other languages like C or Java. This is because Elixir includes built-in functions for managing processes in its standard library, such as send(), which sends information from one process to another, and spawn(), which creates a new process.
Another part of our fault-tolerance strategy is the Nerves framework, an Elixir toolkit for building embedded Linux systems. While Nerves brings a lot of benefits for IoT development, I want to draw attention to its reliability features. Take, for example, AB partitions, where we run our current firmware on one disk partition and write updates to the other one.
When we reboot and switch to the new firmware’s partition, we’ll run a series of checks, such as:
- Did it boot?
- Can it connect to the internet?
- Can we access the device via secure shell (SSH)?
- Can it communicate with the firmware update server?
If the updated device can’t meet these conditions, then it simply reverts to the previous working version. Not only does this stop devices from turning into bricks, but it also gives us the freedom to push out smaller, more frequent patches to fix bugs, make optimizations, or patch vulnerabilities.
The End Game of Connected Products: Exceeding Customer Expectations
When a consumer or a business buys an IoT device, they bring a series of expectations to the table. These can range from a frictionless onboarding experience to expecting it to bring tangible value to their day-to-day, but there’s one thing they always want: longevity. Nobody wants to invest in a product that’s going to keel over in a light breeze.
Some IoT developers approach IoT projects with rose-tinted glasses, imagining that their devices will always function in optimal conditions and that nothing will go wrong. That’s not our philosophy. We always ask the hard questions, figure out what can and will go wrong, and develop a strategy to account for these failures.