WHITEPAPERS
Predictive Maintenance Adoption: Creating and Automating Your Data Engineering Process
Predictive maintenance for connected plants relies on a flow of actionable data, which means that effective, automated data engineering processes are critical. In this whitepaper, we’ll walk you through how our data science team approaches the process.
Author: Justin Gagne
Senior Data Scientist
Justin’s career is centered around continual development. As a Senior Data Scientist at Very, Justin builds reliable production-ready machine learning services.

Predictive maintenance relies on a flow of actionable data, which means that effective data engineering processes are critical. When data engineering for predictive maintenance, data scientists or engineers are tasked with moving data from machine sensors into the cloud. From there it continues through the data pipeline to be cleansed and then ingested by machine learning models. Effective data engineering needs to be reliable and repeatable, which makes it ripe for automation. While a bit of manual planning is necessary in the beginning to determine your goal, once you hit that milestone you can jump into writing code iteratively. In this whitepaper, we’ll walk you through how our data science team approaches the process.
Why Are Plants Adopting Predictive Maintenance?
Predictive maintenance is cutting edge in the manufacturing industry for good reason. Plants that successfully implement predictive maintenance can save as much as 40 percent in costs over plants that use reactive (break/fix) or preventative maintenance strategies. This is because they more efficiently allocate resources while minimizing unexpected downtimes. Predictive maintenance works so well that we consider it an essential step in our IoT Maturity Model. However, we’ve noticed there are a few significant hurdles that most plants need help clearing before they’re able to adopt a predictive maintenance posture.
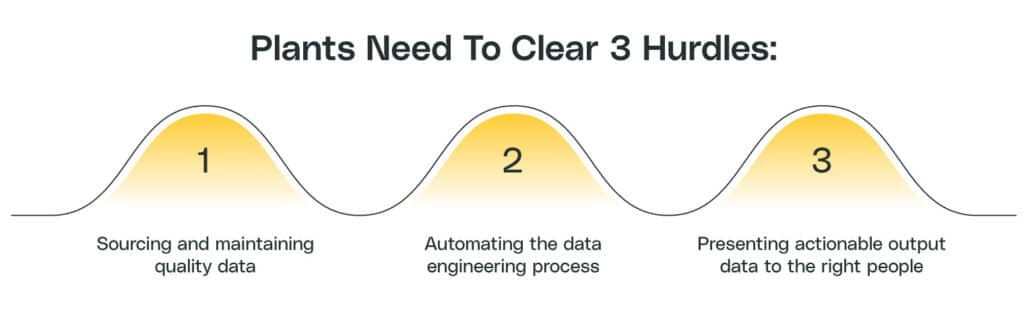
Plants Need To Clear These Three Hurdles
Hurdle 1: Sourcing and Maintaining Quality Data
For most companies, the first hurdle is sourcing and maintaining quality data, which we cover in depth here. Having the right amount of clean data makes an enormous difference in machine learning outcomes and successful predictive maintenance. To solve this problem, we recommend starting simple by taking inventory of your available resources and incorporating new sensors where needed. Once you identify valuable data in the iterative predictive maintenance workflow, additional cleaning of the data and/or increasing its complexity can further increase efficiency and cost savings.
Hurdle 2: Automating the Data Engineering Process
If you begin automating your data engineering process blindly, you can easily introduce technical debt in your system by choosing a data structure that doesn’t match the algorithm you need.
Make sure you have a solid understanding of the problem to be solved before you begin the process of structuring data and constructing your data engineering pipeline. Work with key stakeholders not only to understand the problem but also their requirements. (Spoiler alert: We’ll dive deeper into the data engineering pipeline shortly.)
Hurdle 3: Presenting Actionable Output Data to the Right People
People often tout the power of machine learning, but neglect the delivery. For example, the typical output from a machine learning model is a .csv file. We’ve seen companies put in significant effort to generate data only to have that .csv file buried in a folder somewhere and left to collect dust.
Start your project by defining who needs to use the information. Often the user is in a unique environment. They may be operating machinery and not have access to email or even a traditional computer during their shift. Consider how they will receive the information as you define the ideal output of the tool. What information do they need to see, and in what form do they need to see it?
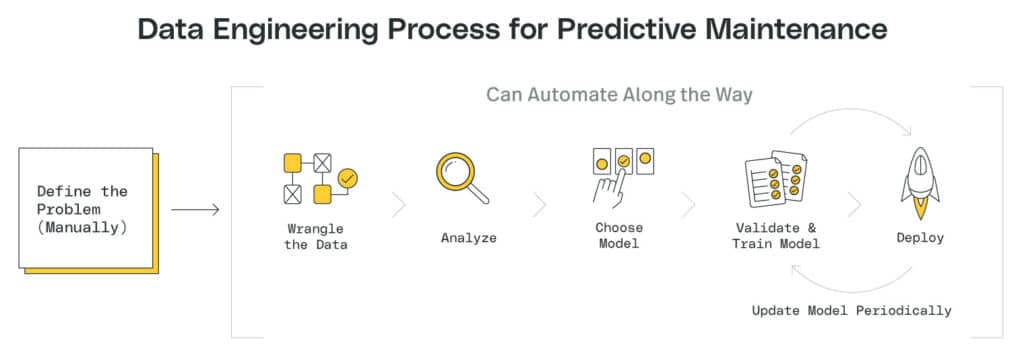
Overview of the Data Engineering Process
So, assuming you’ve cleared the first hurdle (sourcing quality data), the next hurdle to clear is constructing and automating the data engineering process. While data scientists and engineers typically own this element of setting up a predictive maintenance program, they’ll need to consult numerous other stakeholders along the way. Here’s an overview of what that process looks like.
Step 1: Analyze the Problem
It all starts with a clear definition of the problem. Your data science or engineering team should interview plant operators and decision-makers to better understand the problem and how best to solve it. Discuss sensors and data extraction with hardware engineers and chat with the infrastructure team to make sure the data pipelines flow smoothly into production.
Thorough documentation at this early stage, and along the way, will streamline software development once you begin the automation process and increase efficiency across all nodes in the pipeline — each of which accepts, transforms, and finally transfers data downstream. What you can accomplish manually in a data engineering process you can almost always automate, especially when all parties in the process are on the same page.
After determining the failures you need to predict, consult again with subject matter experts to isolate the data most likely needed for that prediction. If you’re unsure what data is most relevant at this point, err on the side of too much, knowing that you will optimize the process in subsequent iterations.
With these inputs in mind, articulate your goals for this first deployment. How should the machine learning algorithm inform decision-makers? What outputs and formats are most useful to them? Now is also a great time to consult app designers and other teammates who may be involved later in the data engineering process.
Step 2: Wrangle Data
Where Is the Data Sourced From?
Now that you’ve articulated your problem and goals, you can develop a pipeline that ingests and prepares the data. First, determine if the data you need is already recorded by active plant devices. If not, install appropriate sensors where you need additional monitoring. To optimize cost savings, choose sensors best suited for the machine learning algorithm and plant environment. For example, investing in sensors with adequate resolution and accuracy is worth it, whereas overspending on sensors with bells and whistles that don’t have high environmental tolerance (ability to tolerate dust, humidity, high temperatures, etc.) is usually not.
It’s worth mentioning again that, ideally, you’ve already ensured that quality data is being collected before jumping into the data engineering process (see hurdle #1 above).
Why Clean, Structure, and Label the Data?
Raw data is rarely the best diet for machine learning algorithms. In addition to duplicates and missing data, incorrect data types may throw errors in downstream processing. To minimize headaches, we recommend manually reviewing individual data points to identify and remedy the abnormalities. Keep a running list of these operations for automating in the future.
Next, structure and label your data in ways most amenable to the data processing algorithm. Labeling involves tagging raw data to establish data classes so that machine learning models can identify and properly categorize the same type of data when encountered later without labels. Keep in mind that ultimately you’ll be automating the entire process, so establish conventions that allow data to flow smoothly downstream without manual intervention.
Step 3: Analyze Data
Our goals during analysis are to identify trends in the data and inform how we build and train the machine learning model. Data analysis is as much art as science, so we suggest teaming up with a data scientist when analyzing data for the first time.
Why Organize the Data Again?
Maintenance prediction relies on well-organized and descriptive data. Feeding the algorithm a million data series will not be as efficient, nor as successful, as classifying the data in ways that enhance the algorithm’s ability to determine meaningful, actionable next steps.
This point in the process is a great opportunity to examine the existing labels (aka classes). Determine if they are accurate enough and if they are sufficient volume for you to make reliable predictions about the performance of the part or machine that you’re trying to predict. You may need to adjust your approach, adding labels to provide more options for analysis, or removing labels to simplify your data set and reduce costs.
How Can Common Math Approaches Be Leveraged Here?
Several mathematical approaches can frequently reveal useful info about your data, including correlation analysis, distribution shapes, principal component analysis, and time series analysis. Additionally, as long as proper inputs are used and results are interpreted correctly, many software tools can perform these computations for you.
Step 4: Select a Suitable Machine Learning Model
Analyzing the data is a powerful tool for deciding which machine learning models are most appropriate. In addition to data insights for model selection, however, we recommend reminding yourself of the problem you aim to solve and how the outputs will be presented.
What Models Will the Data Support?
Supervised machine learning algorithms depend on independent “x” variables (the input) and dependent “y” variables (output).
The choice of machine learning algorithm is guided by the data. For example, a supervised learning model – which tends to be more accurate than an unsupervised model – requires labeled historical data for both independent and dependent variables. These labeled data act as the ground truth for supervised models during training.
Alternatively, especially at the beginning of projects, organizations may not have realized the importance of saving historical outcome labels required for supervised learning. Under circumstances where they only have access to sensor data as model inputs, unsupervised models – which find concealed patterns in unlabeled datasets – can provide initial guidance for maintenance predictions and improving data labeling practices.
An Example: Detecting Fraud in Online Lending Applications
One common use case for machine learning models is detecting fraud in loan applications. Ideally, the lender would use supervised learning based on labeled historical x’s and y’s. But this is where most companies fall short — while many have the historical data, they haven’t applied labels. Sometimes companies are able to solve this by labeling with automated scenarios. But if not, or if there’s no significant amount of historical x’s and y’s to begin with, the lender will have to rely on unsupervised learning to find patterns that indicate a likelihood of fraud.
When the relationship between the independent and dependent variables is not easy to ascertain, data scientists may build heuristic models after testing hypotheses provided by subject matter experts. In this example of a loan application submitted online, variables to test include the distance of the applicant from the associated property, age of the applicant and age of email address, etc.
What Problem Do You Aim To Solve?
After all, isn’t this why we started this exercise in the first place? The nature of the problem you want to solve influences the choice of machine learning model. For example, if you wish to predict a machine failure based on comparisons between current and historical data, the model should output a classification rather than anomaly detection or time series forecasting.
How Will You Present Model Results?
If your organization prefers to understand the factors that influence a model’s output, we suggest choosing a more interpretable model such as a decision tree or logistic regressor that allows you to understand exactly why the algorithm made the classification that it did.
On the other hand, if the quality of the prediction is most important to you, a more complex and accurate black box model such as a deep neural network or random forest may be a good fit.
Step 5: Train & Validate the Model
Train your model by feeding it a series of matched inputs and outputs. These examples teach the model how outputs relate to inputs, enabling it to accurately predict future outputs from new inputs. We recommend splitting your data into two sets, 70 percent for training the algorithm and 30 percent for validating.
If the validation results are poor, gather more data, reconsider your engineering process, or try a different ML algorithm/approach.
Step 6: Deploy, Improve, Rinse, Repeat
Model deployment can take many different forms. For example, you can host it in the cloud with results delivered via SaaS application, or you can run it on the device itself and automatically send maintenance alerts. Regardless of specifics, in order to utilize all of a machine’s useful lifetime and minimize downtime and repair costs, we recommend taking advantage of the data and information you acquire along the way. Periodically update your model so it doesn’t become stale, starting back with retraining.
What If the New Model Makes Things Worse?
A useful framework for managing unexpected or adverse effects resulting from a new model deployment is a blue/green deployment strategy. Under this scheme, the plant is divided into two separate but identical environments: the blue environment runs the current model while the green tries out the new model. In this way, deployment risks are minimized while still allowing potential improvements.
How To Decide Which Model Is Better?
Remember the bigger picture of all this data engineering: solving a business problem to optimize the predictive maintenance schedules of valuable plant assets. One useful perspective considers whether your operations are more sensitive to false positives or false negatives. In other words, which is more costly: unexpected downtime or unnecessary maintenance?
Keeping these considerations in mind is critical for increasing the bottom line. If a model does not accomplish that, iterate through these steps and try again.
Now, It’s Time To Leverage the Insights
Once trained, an automated machine learning model analyzes vast amounts of data with minimal to no human intervention. With this automated resource you’ll be able to optimize your predictive maintenance workflow — reducing costs and machine downtime, mitigating risks, and increasing employee and manufacturing efficiency.
However, building and automating an effective data engineering process can be challenging to those unfamiliar with the complexities of data science, data engineering, and machine learning. At Very, we’ve established a reliable approach to deliver value quickly while iterating together to improve your return over time.