BLOG
Trial and Error: An Iterative Approach to Developing Alexa Skills
Recently, Thrive Global engaged Very to build an Alexa skill. Full disclosure: I had never worked on the Alexa platform, and I had no real interest in smart home devices- Echoes and Dots be damned.

Launching a Global Media Platform
Thrive Global chose Very to design and develop their robust digital platform in just 12 weeks.
But as we got deeper into the project, I was changing my tune. Now, I can honestly say that building on the Alexa platform has deepened my love for programming and given me a newfound respect for our cloud-based bots.
The Requirements
Our client needed an Alexa skill that would guide the user through a series of steps, then play an audio file. The file contained instructions that could not be completed unless the user had followed the guided steps.
When we kicked off the project, our client already had scripted out the interaction between the user and the Alexa device. The script was static, but the client wanted to iterate quickly, adding in new functionalities. The goal was to engage users in the Alexa skill so that they would continue to reuse the application.
The Wrong Approach
Because we had never worked with the Alexa platform, my partner and I wanted to understand how other people were building Alexa skills. So we began with research spikes – a Blog Driven Development approach. This was great for learning, but we knew that it wasn’t going to be a satisfactory long-term solution because the examples given in the blogs were very basic. We would need to write a lot more code to end up with the same solution, and it would have been really hard to test.
We chose the tech stack we would use (an AWS Lambda function deployed using the Serverless framework); learned how to setup an Alexa skill in the Amazon Developer Portal;, and gained a basic understanding of the request/response cycle of Alexa skills. Then, we prototyped.
It wouldn’t be trial and error if we didn’t start with a trial and an error. Before we had even gotten to the second step in the script, we realized the development pattern that was unfolding in front of us – and the horrors we were about to face.
We Were Writing a Lot of IF Statements
If you’ve been programming for a while, you know that a significant number of bugs in your applications come from conditional “if” statements, because it’s hard to account for every situation and combination of values.
This was our first indication that we were venturing down the wrong path.
We Were Nesting a Lot IF Statements
If there’s anything worse than a bunch of conditional logic in an application, it’s nested conditional logic.
Nested conditional logic makes the application hard to debug, resistant to change, and difficult to test: a not-so-great combination that inevitably leads to embarrassing bugs in production.
And We Had a Lot of Duplicated Code
Programmers love acronyms, and one of our favorites is DRY: Don’t Repeat Yourself. Basically, we want to reuse as much code as possible, so that we’re not reinventing the wheel over and over again.
But as we were prototyping, that mantra went out the window. Just to get something working – and to determine when the user needed a response – we were performing a lot of duplicated checks.
There Had to be a Better Way
Too many if statements, too much duplicated code – clearly, something wasn’t right. Once we identified those issues, we knew we had to stop, step back, and come in from a different angle.
With fresh eyes – and slightly bruised egos – we revisited the original requirements. And we had a thought: just because the script workflow is static, doesn’t mean that the code should be static and hard coded.
In that moment, we began to see the script not as a script, but as a workflow. Suddenly, it became painfully obvious that script was nothing but a state machine.
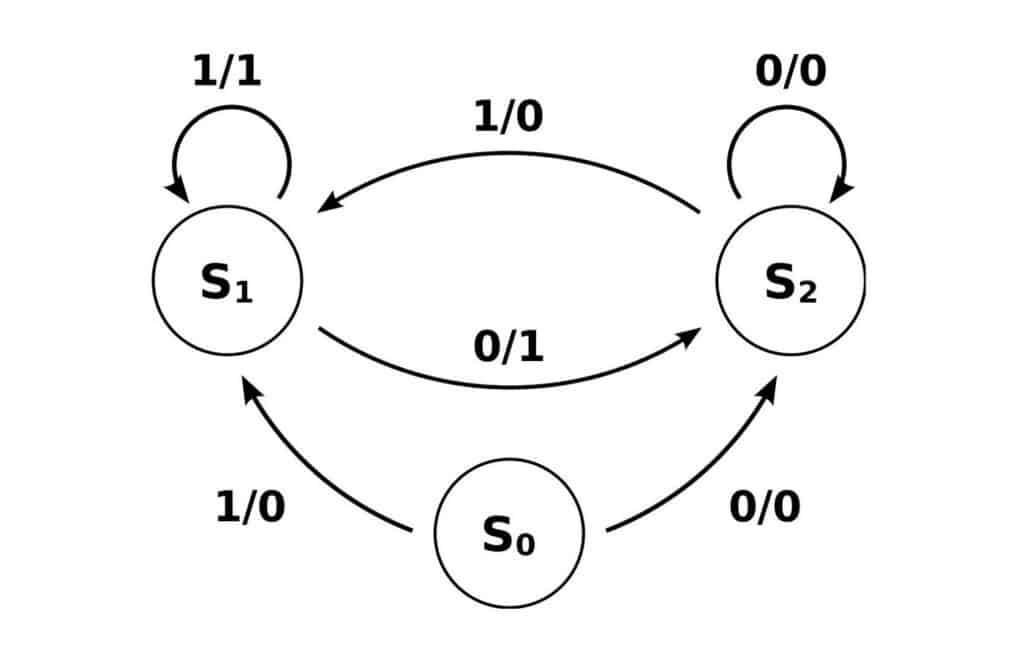
What is a State Machine?
Good question. A state machine is very similar to a workflow diagram. Each node in the diagram represents some kind of state. Each state can have a vast array of properties, with the most important in our use case being output and how to get to the next state. An example state diagram is pictured below.
The Better Way
Once we realized the script was a state machine, we threw away our previous code and started from scratch:
- We created a custom configuration schema for the script.
- We wrote the code so that when a user invokes the skill, it looks for the current state in the session, then looks up that state in the configuration file.
- Next, we take the intent from the request and examine the branches for the current state to determine the next state.
- Once we have the next state, we update the current state to match the next state and return the output for the new current state.
We’re happy to report that this approach was a vast improvement on our initial attempt. But it wasn’t perfect.
We Were Performing a Lot of Data Manipulation
Since we had defined our own custom schema, we had to translate it to the Alexa platform schema. This meant we had to do a lot of data manipulation and data mapping to fit the values to the Alexa schema. It worked for us and kept the configuration file DRY, but it created another problem.
Changes to the Alexa Platform Resulted in Major Code Changes
Since we were trying to deploy the skill on a tight timeline, we were very reliant on the Alexa platform. Maybe a little too reliant. If the platform were to change, we would have to change our data manipulations to fit the new schema – which would be incredibly costly.
Our Final Solution
Once we identified those issues, we realized we didn’t need to DRY the configuration file. Instead, we used the Alexa platform’s schema directly inside of our schema. It proved to be the right decision, and it delivered quite a few benefits.
Seamless Updates
Since we were no longer a slave to our own schema, we were immediately able to take advantage of the full Alexa platform without having to make any code changes. Anytime the Alexa platform releases new functionality, it was already available for us to use just by updating the output of our states.
Faster Development
Since all the application logic does is manage state transitions, we found that we were able to build the Alexa skill, and iterate on new requirements, much more quickly than if we had hard coded the responses. This also meant that our product advisor was capable of making minor changes without us since there was no code to update, but rather a few sentences in the configuration file.
No Conditional Logic
We were able to remove almost all traces of conditional logic throughout the skill. The only time conditionals are used now are to make sure environment variables are properly set, if the skill is in the middle of a current session, or if a requested state exists. That is it!
Easy Testing
As a result of managing state transitions and receiving predictable output, we are able to fully test the input and output of the skill to ensure the workflow follows what the client has defined. This way we can test the code, and the state progression of the configuration to actually test the flow of the application rather than just unit tests.
The Best Possible Outcome
After work concluded on the initial version of the Alexa skill, we found that we had developed a great tool that was general enough to use when building any Alexa skill. So we decided to keep it.
We extracted all of the state machine logic into a framework we call lazysusan – because every time the skill spins, it is as a new state, giving the user the desired output.