BLOG
Using Bayes’ Rule to Boost AWS Rekognition’s Confidence

At Very, our engineering team executes client builds in a lean manner, following agile development processes. This framework ensures that we continuously deliver value through functional software solutions that can pivot whenever our clients’ business needs evolve.
Development projects that involve machine learning are no different. This means our data scientists must be discerning when they’re selecting tools and algorithms. Always, their choices should provide the client with the optimal ratio of time spent versus algorithm performance.
In the case of Hop, a current client, we were tasked with developing a facial recognition engine to verify customer identities for automated draft beer distribution kiosks. The client had a strong preference for AWS Rekognition due to some research he performed prior to our engagement.
Rekognition is an extremely powerful platform, and it promises scalability and functionality that would circumvent countless data science and software engineering hours. It seemed like a good fit, so we took the time to build an experiment in our favorite experimentation environment, Jupyter Notebooks.
First Impressions
The purpose of this system is Identity Verification, which means that when the system is queried, we’ll essentially be asking, “Does this face belong to the person whose identification credentials have been presented?” For this task, the Compare Faces feature of Rekognition is needed.
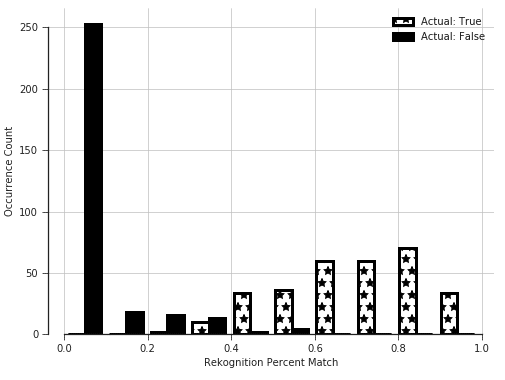
To get an initial feeling for the performance of the Compare Faces feature, we did a simple experiment with 105 pairs of photos of an extraordinarily un-photogenic person: me. The results are illustrated in the histogram below.
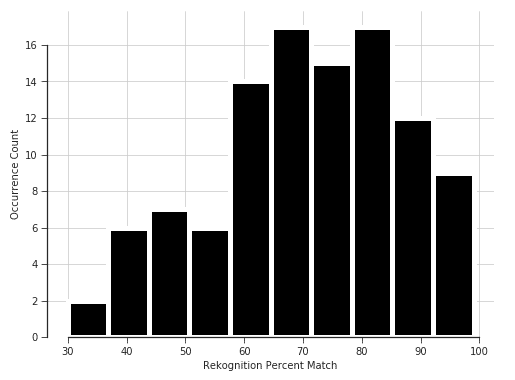
Though this was an initial exploratory analysis, we can see that there is a high variance, and a large portion of the distribution lies below 80% match. This is especially troubling because by default, AWS only returns matches of greater than 80%, which would lead us to believe that 80% is the minimum threshold for a “match.”
Next, we performed the inverse of this test: 100 pairs of photos of myself and people who are not me.
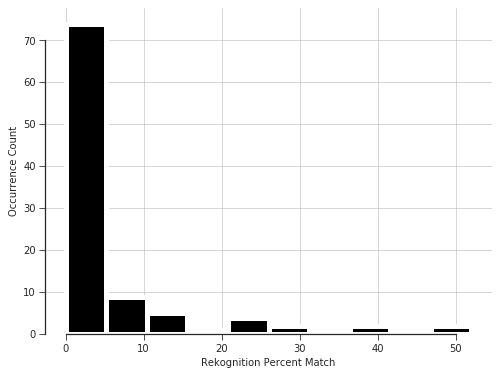
High Precision: Percent match on image pairs of different people
Final Observations
- The boto3 implementation of Rekognition has a known short-coming in that it does not support asynchronous requests. There are different ways of designing your application to prevent this from slowing down your production code, but for prototyping with the CompareFaces feature, it caused a rather annoying bottleneck.
- The expected recall of the Rekognition comparison API has a wide variance on this dataset and is very likely to reject a majority of occurrences of the same person if the percent match threshold is greater than 70%.
- The expected precision of the Rekognition comparison API is very high, but depending on the percent match threshold chosen, there could be some false positives. (We’ll get to a precision/recall curve later.)
Bayesian Inference
After this initial experiment, it seems that out of the box Rekognition will be great at making sure that beer is never poured for someone it shouldn’t be (precision), but it will possibly fail miserably at pouring beer for someone it should (recall). If the classification threshold is reduced to improve recall, it could negatively impact precision, resulting in a small number of undesired pours.
This is a limitation with one-shot classification using Rekognition. However: while there may be no free lunch, you can always pay more for better lunch. It is possible to leverage Bayesian Inference to achieve more accurate estimations over multiple observations. Multiple observations can be achieved by creating a collection of faces for each individual user, then comparing the “query” face to every face in the collection.
In order to limit complexity of the initial implementation, each match percentage observed from Rekognition was treated as the probability that the querying face belongs to the same person who created the reference images. This allowed us to follow a simple method for Bayesian style probability estimates.
Using this method yielded more confident predictions.
The above image shows essentially the same two plots that you’ve already seen, but now they share the same set of axes and are colored based on labels. The figure below shows how Bayesian inference all but eliminates uncertainty creating a nearly perfect binomial distribution matching the proper labels.
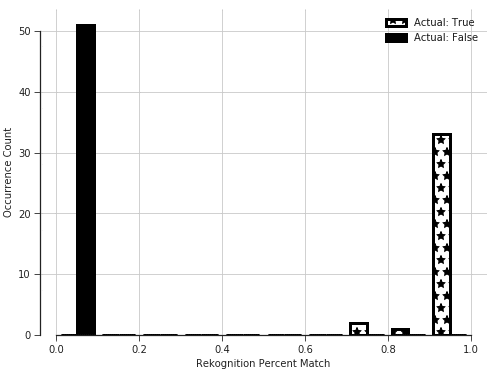
Bayesian Inference Comparing Query Image to 5 Reference Images
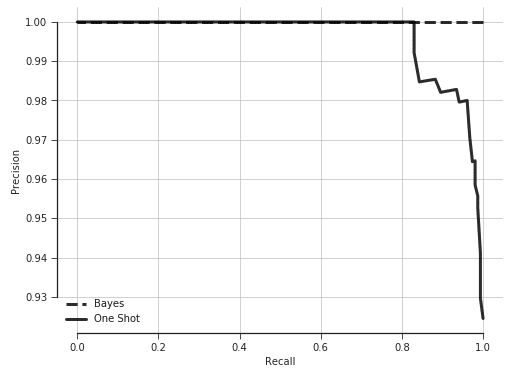
Lastly, the Precision vs. Recall curves show that for a one-shot prediction, if recall much greater than 0.8 is desired, precision will be sacrificed. While this is not poor performance, it means that somewhere between 1 in 10 or 1 in 5 users will need to initiate a facial scan a second time before beer can be poured, which could be an off-putting user experience. For our experimental dataset, it can be seen that Bayesian inference is capable of achieving perfect precision and recall.
Final Thoughts
Because Very focuses on maximizing business value within a given amount of client resources, our initial investigation was not rigorous in terms of number of samples or variety of images. However, it was performed at a rapid pace (less than four hours billed to the client) and allowed a simple but highly effective solution to be brought into production quickly (three days billed to the client).
The focus on delivering client value also means that the best choice here was to leverage an off-the-shelf facial recognition platform and bend it to our will with some simple probability.
As much as our inner academics would like to go on a long search for a custom model beginning with ‘import keras,’ it simply doesn’t make sense. But as Hop’s users and application complexity increase, a more rigorous analysis will be performed across a much larger dataset — which may yield an improved strategy, if necessary.
Once more data is collected, we hope to move forward with informed priors based on a deeper analysis of Rekognition.