BLOG
Man is to Programmer as Woman is to Homemaker: Bias in Machine Learning
We often hear about gender inequities in the workplace. On average, women are paid less than men and advance in their careers more rarely. In 2015, the New York Times reported that fewer women ran S&P 1500 firms than men named John.
A lot of factors are at play: the persistence of traditional gender roles (for both men and women), unconscious bias, blatant sexism, lack of role models for girls who aspire to lead or take on less traditionally “female” roles like computer programming.
But could our technology itself be partly to blame? A study titled, “Man is to Computer Programmer as Woman is to Homemaker?” found that machine learning has the potential to reinforce cultural biases. In it, researchers found that a natural language processing program trained on Google News articles exhibited gender stereotypes to, “a disturbing extent.”
To understand how this happened, we have to learn a little bit about a neural network called word2vec. I’m not a data scientist, but we have some really awesome data scientists at Very who patiently explained how it works. Here’s the break down.
What is word2vec?
Image and audio processing systems work with rich, high-dimensional datasets. For tasks like object or speech recognition, all the information required to analyze the file’s contents is encoded in the data.
But processing written language doesn’t work the same way. Each word is a combination of characters, which have very little meaning when taken on their own. The fact that “c”, “a”, and “t” are combined to make the word cat, gives us no information about what a cat may be or how it is similar to a dog.
Google needed a better way to understand the relationships between words, so in 2013, researchers created something called word2vec. This neural network was built to help with natural language processing – a computer’s’ ability to understand human speech.
Word2vec falls into a special category of neural networks called autoencoders. Autoencoders work kind of like compression. You put something into an autoencoder (in this case, words), and you compress them down to a representation that contains all the information you need to replicate that same word.
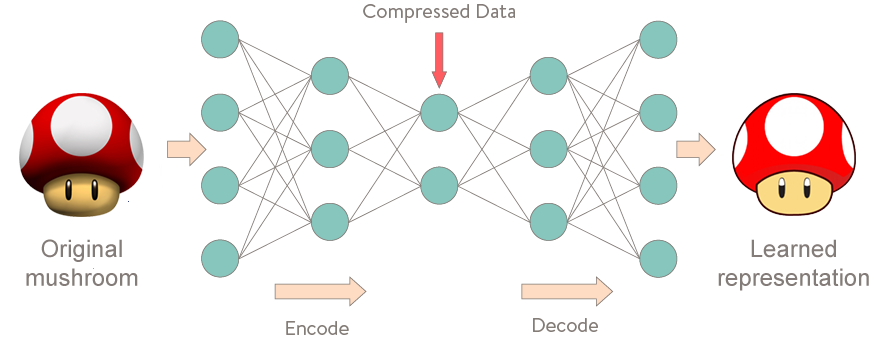
Once researchers devised the word2vec architecture, they needed to train it. Luckily, they had a massive data set at their fingertips. They had the neural network train on Google News articles to learn relationships between words. And it worked!
Word2vec was able to provide numeric vector representations of words, and those vectors could be used to make calculations like: “If you take the word ‘king’ and subtract ‘man’ and add ‘woman,’ what do you get?” The result is obviously the word “queen,” and these vector embeddings provide similar meaning through almost the entire English language.
The embeddings also allow us to make simple calculations to identify complex relationships. For instance, given the word problem, “Paris is to France as Rome is to ____,” simple vector math will tell you “Italy” as the answer.
Word2vec was widely accepted and many pre-trained vector embeddings were then incorporated into all sorts of other software, including recommendation engines and job-search systems.
Is the Machine Sexist?
However, when researchers started to dig into the word2vec trained on Google News (known as w2vNEWS), they found some more troubling correlations. Correlations like, “Man is to woman as computer programmer is to homemaker,” and “Man is to woman as boss is to receptionist.”

The trouble wasn’t the machine itself — it was working perfectly. Nor did the engineers’ intentional or unintentional bias make its way into the software. Instead, the problem was that the program picked up on the biases inherent in the news being reported on Google News. The word “homemaker” appeared more frequently with the pronoun, “she” than with “he,” so it was more closely associated with female-ness than male-ness.

Any time you have a dataset of human decisions, it includes bias,” said Roman Yampolskiy, director of the Cybersecurity Lab at the University of Louisville. “Whom to hire, grades for student essays, medical diagnosis, object descriptions, all will contain some combination of cultural, educational, gender, race, or other biases.”
While that’s a bit troubling, it doesn’t seem like an earth shattering problem. Until you think about all of the systems that use word embeddings to understand language — including chatbots, recommendation algorithms, image-captioning programs, and translation systems. Studies have shown that bias in training data can result in everything from job-search advertisements showing women lower paying jobs than men to predictive policing software that disproportionately rates people of color as likely to commit crimes.
Kathryn Hume, of artificial-intelligence company Integrate.ai, calls this the “time warp” of AI: “Capturing trends in human behavior from our near past and projecting them into our near future.”
Debiasing Word Embeddings
A simplistic approach to solve this problem would be to simply remove the “gender dimension” from all the words to essentially take all gender out of your data. But gender differences aren’t inherently a problem. The kind of difference that makes “king” and “queen” different isn’t so troubling. But there are definite problems with “computer programmer” and “homemaker.”
Instead of removing all gender from the words, researchers wanted to identify the difference between a legitimate gender difference and a biased gender difference.
So researchers set out to disentangle the biased gendered terms from the unbiased ones. They explain it like this: if there’s a “gender dimension,” then that dimension can have shape to it. They treat bias like a warp on the gender space that affects different types of words. They set out to identify the terms that are problematic and exclude them while leaving the unbiased terms untouched. This method is called “hard debiasing.” By doing this, they were able to remove a lot of bias from their dataset while keeping the structure of their data.
To learn more about their approach and the results, check out the full study here.
Great Power, Great Responsibility
In researching this study, I talked to Jeff McGehee, director of engineering at Very. I asked him if Google fixed the problem with w2vNEWS, and he said it would be impossible to know if all the vector embeddings people use in their software would be fixed even if Google corrected the bias.
But Jeff said there’s a good chance that data scientists using w2vNEWS in their own software had already identified this hidden bias and taken action in order to reduce its impact. He said, “If I was building something where gender bias would have significant impact, that’s the first question I would’ve asked.”
This highlights the importance of having trained data scientists building products that leverage machine learning. Bias in training data can be mitigated, but only if someone recognizes that it’s there and knows how to correct it.
Today, it’s easier than ever for any software engineer to add natural language processing or facial recognition to their products. It’s also more important than ever to remember that the products we build can project the biases of today onto the world we live in tomorrow.