BLOG
DevChat: Building IoT Developer Tools for Experiments

No one is an island — especially when it comes to building IoT products and data science solutions. Every day at Very, our data scientists and our hardware and software engineers face unique and complex challenges. Solving these problems requires multidisciplinary knowledge and a heightened awareness of how time is spent.
As a remote-only team, we don’t have the luxury of dropping by one another’s desks to talk things out. So, we came up with something that I think is even better, particularly for people who spend most of their time on focus-work: a dedicated Slack channel where developers can collaborate and share their combined decades of experience at their convenience. We call it #dev_chat.
What follows is a story about a challenge I recently faced on a client project and the path I took to a solution. I shared some important lessons I learned along the way in our #dev_chat channel, and the senior engineers on our team had some thoughtful responses as well.
The Challenge
On a recent client project, our team was getting ready to build a feature that involves querying large amounts of time series data from Postgres and charting it in the front end.
Upon investigating the table where this data was stored, I noted that the columns were:
device_serial_number:string
monotonic_time:int
timestamp:utc_datetimedata:jsonbThe data column contains key/value pairs of metrics we were storing such as
{"machine_rpm": 200, "machine_running": true}The queries we needed to make would involve selecting a given metric (machine_rpm) for a given device_serial_number over a time window. The table would contain approximately one record per second per device (luckily at the time, our IoT device count was low).
Building a Quick IoT Developer Tool to Experiment with Solutions
I immediately knew that the jsonb field is not optimal for these types of queries, and the best schema to address grabbing data in this way is a star schema, but it seemed undesirable to make that drastic of a migration when the goal was to close the project out as quickly and efficiently as possible, and this charting feature was the last feature in our way.
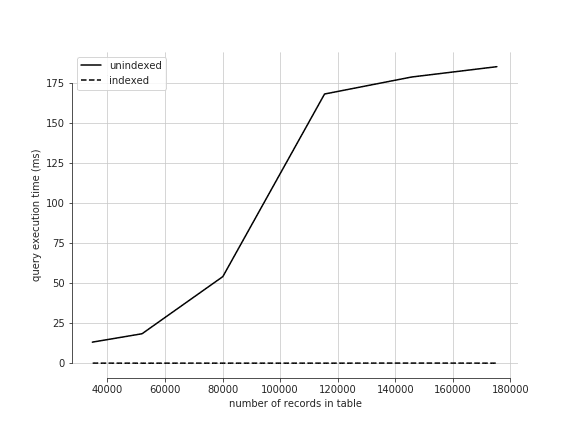
I also noted that there was a multi-index on [device_serial_number, monotonic_time, timestamp], but the timestamp was not indexed individually. This meant that slicing by time alone would not be very efficient. Since adding an index is very simple, I decided to do a quick investigation of the expected performance difference in queries before and after adding an index on the timestamp field. The results of the experiment are in the chart below.
Lessons Learned: The Value of Investing in Dev Tools
I already knew that indexes are important for efficient queries, but the results of my experiment told me how important they really are. I wasn’t extremely rigorous in my testing (e.g., I didn’t run the query multiple times for a given number of records), but it’s extremely clear that an index gave me two giant advantages here:
- Constant time queries as a function of the number of DB records.
- Faster queries for any number of records.
I knew this would be unsurprising to most of the Very team, but it’s still important to reinforce. In addition, there was another big lesson lurking here:
A multi-index does not provide the same type of performance gains as a single column index.
Again, this may have been unsurprising, but if anyone was not aware, this would be an easy mistake to make. Multi-indices really only pay off if you are querying by every field in the index. The ordering of the fields matters, too, because you can get benefits from the multi-index if you query from the first fields in the index.
Lastly, the lesson that I wanted our team to internalize was that taking the time to build a very quick tool that simulates real pseudo-random device data allowed me to perform an experiment in less time than it took me to do this write-up. Investing in our developer tooling to help us perform quick experiments nearly always pays off.
Based on this information that I gathered, I felt confident in moving forward with only adding an index and perhaps caching some query results if needed in order to implement this feature (as opposed to a full restructuring of the schema used for storing our time series data).
Insights from the IoT Development Team
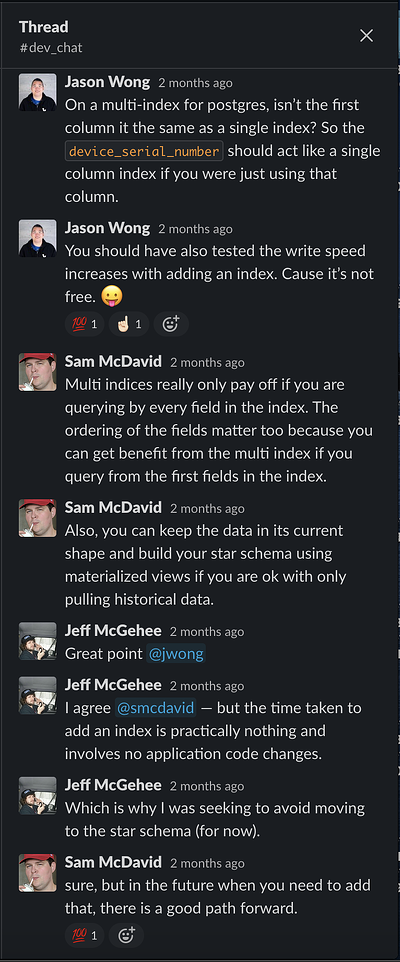
After I shared a write-up of the above challenge and solution in the #dev_chat channel, a few of our senior engineers made some great points on how to iterate on my approach and prepare for a good path forward in the project.
Specifically, they pointed out the importance of testing the write speed increases of adding an index because of the associated costs. They also noted that while this was the right approach for the situation at hand, using a star schema will provide a good path forward.
Check out a snippet of the conversation here — emojis and all:
Work With Expert IoT Developers
We treat every client project with the high level of precision and accountability that you see reflected in this post. Tell us about your project today.